
Part C: Prepare The Dataset
Multi-Topic Text Classification with Various Deep Learning Models
Author: Murat Karakaya
Date created….. 17 09 2021
Date published… 15 03 2022
Last modified…. 15 03 2022
Description: This is the Part C of the tutorial series “Multi-Topic Text Classification with Various Deep Learning Models” that covers all the phases of text classification:
- Exploratory Data Analysis (EDA),
- Text preprocessing
- TF Data Pipeline
- Keras TextVectorization preprocessing layer
- Multi-class (multi-topic) text classification
- Deep Learning model design & end-to-end model implementation
- Performance evaluation & metrics
- Generating classification report
- Hyper-parameter tuning
- etc.
We will design various Deep Learning models by using
- the Keras Embedding layer,
- Convolutional (Conv1D) layer,
- Recurrent (LSTM) layer,
- Transformer Encoder block, and
- pre-trained transformer (BERT).
We will cover all the topics related to solving Multi-Class Text Classification problems with sample implementations in Python / TensorFlow / Keras environment.
We will use a Kaggle Dataset in which there are 32 topics and more than 400K total reviews.
If you would like to learn more about Deep Learning with practical coding examples,
- Please subscribe to the Murat Karakaya Akademi YouTube Channel or
- Do not forget to turn on notifications so that you will be notified when new parts are uploaded.
- Follow my blog on muratkarakaya.net
You can access all the codes, videos, and posts of this tutorial series from the links below.

PART C: PREPARE THE DATASET
You can watch this tutorial using the below links in English or Turkish:
Remember the raw dataset
After operations in Part A, the raw dataset statistics are as follows:
data.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 422281 entries, 0 to 427230
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 category 422281 non-null object
1 text 422281 non-null object
2 words 422281 non-null int64
dtypes: int64(1), object(2)
memory usage: 29.0+ MB
time: 92.3 ms (started: 2022-03-01 12:16:13 +00:00)data.describe()
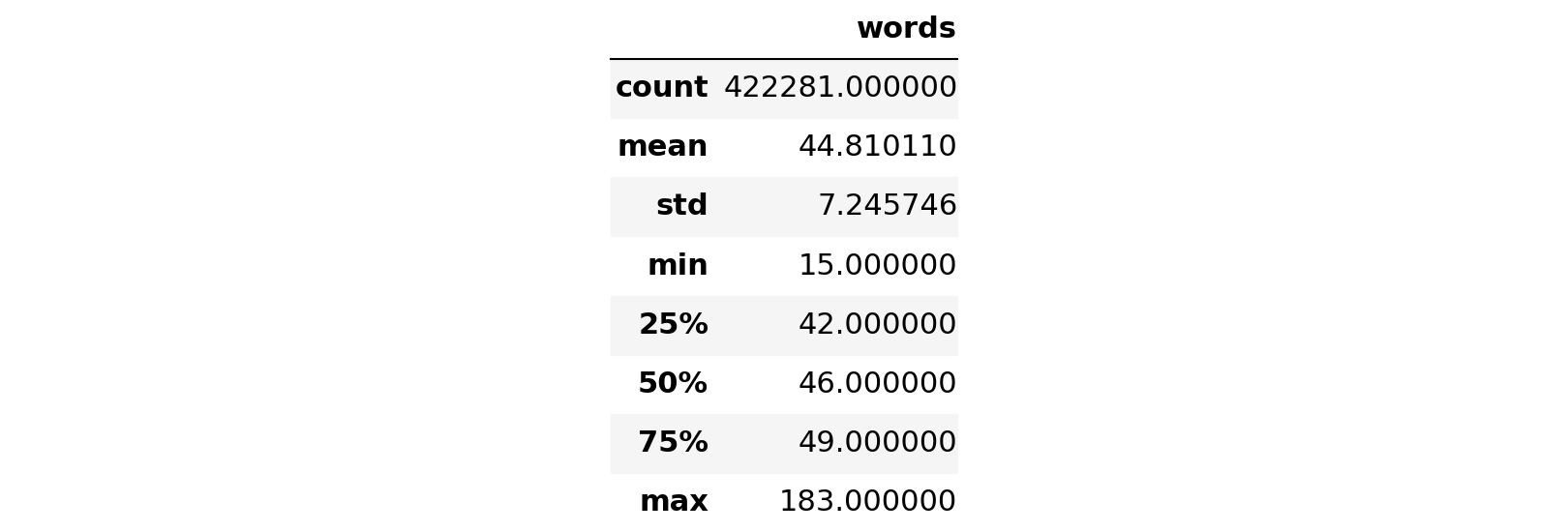
time: 37.1 ms (started: 2022-03-01 12:16:13 +00:00)Shuffle Data
It is a really good and useful habit that, before doing anything else, as a first step in the preprocessing shuffle the data!
Actually, I will shuffle the data at the last step of the pipeline. But it does not harm shuffling the data twice :))
data= data.sample(frac=1)time: 106 ms (started: 2022-03-01 12:16:13 +00:00)
Convert Categories From Strings to Integer Ids
Observe that the categories (topics/class)of the reviews are strings:
data["category"]27032 beyaz-esya
396362 temizlik
54487 cep-telefon-kategori
34124 beyaz-esya
367759 sigortacilik
...
363263 sigortacilik
338102 otomotiv
285630 mekan-ve-eglence
39221 beyaz-esya
343939 otomotiv
Name: category, Length: 422281, dtype: object
time: 10.8 ms (started: 2022-03-01 12:16:13 +00:00)
Create integer category ids from text category feature:
data["category"] = data["category"].astype('category')
data.dtypescategory category
text object
words int64
dtype: object
time: 56.2 ms (started: 2022-03-01 12:16:13 +00:00)data["category_id"] = data["category"].cat.codes
data.tail()

time: 29.3 ms (started: 2022-03-01 12:16:13 +00:00)data.dtypescategory category
text object
words int64
category_id int8
dtype: object
time: 8.03 ms (started: 2022-03-01 12:16:13 +00:00)
Build a Dictionary for id to text category (topic) look-up:
id_to_category = pd.Series(data.category.values,index=data.category_id).to_dict()
id_to_category{0: 'alisveris',
1: 'anne-bebek',
2: 'beyaz-esya',
3: 'bilgisayar',
4: 'cep-telefon-kategori',
5: 'egitim',
6: 'elektronik',
7: 'emlak-ve-insaat',
8: 'enerji',
9: 'etkinlik-ve-organizasyon',
10: 'finans',
11: 'gida',
12: 'giyim',
13: 'hizmet-sektoru',
14: 'icecek',
15: 'internet',
16: 'kamu-hizmetleri',
17: 'kargo-nakliyat',
18: 'kisisel-bakim-ve-kozmetik',
19: 'kucuk-ev-aletleri',
20: 'medya',
21: 'mekan-ve-eglence',
22: 'mobilya-ev-tekstili',
23: 'mucevher-saat-gozluk',
24: 'mutfak-arac-gerec',
25: 'otomotiv',
26: 'saglik',
27: 'sigortacilik',
28: 'spor',
29: 'temizlik',
30: 'turizm',
31: 'ulasim'}
time: 385 ms (started: 2022-03-01 12:16:13 +00:00)
Build another Dictionary for category (topic) to id look up:
category_to_id= {v:k for k,v in id_to_category.items()}
category_to_id{'alisveris': 0,
'anne-bebek': 1,
'beyaz-esya': 2,
'bilgisayar': 3,
'cep-telefon-kategori': 4,
'egitim': 5,
'elektronik': 6,
'emlak-ve-insaat': 7,
'enerji': 8,
'etkinlik-ve-organizasyon': 9,
'finans': 10,
'gida': 11,
'giyim': 12,
'hizmet-sektoru': 13,
'icecek': 14,
'internet': 15,
'kamu-hizmetleri': 16,
'kargo-nakliyat': 17,
'kisisel-bakim-ve-kozmetik': 18,
'kucuk-ev-aletleri': 19,
'medya': 20,
'mekan-ve-eglence': 21,
'mobilya-ev-tekstili': 22,
'mucevher-saat-gozluk': 23,
'mutfak-arac-gerec': 24,
'otomotiv': 25,
'saglik': 26,
'sigortacilik': 27,
'spor': 28,
'temizlik': 29,
'turizm': 30,
'ulasim': 31}
time: 8.54 ms (started: 2022-03-01 12:16:14 +00:00)
Check the conversions:
print("alisveris id is " , category_to_id["alisveris"])
print("0 is for " , id_to_category[0])alisveris id is 0
0 is for alisveris
time: 2.76 ms (started: 2022-03-01 12:16:14 +00:00)
Check the number of categories
It should be 32 as we observed in the raw dataset above:
number_of_categories = len(category_to_id)
print("number_of_categories: ",number_of_categories)number_of_categories: 32
time: 2.82 ms (started: 2022-03-01 12:16:14 +00:00)
Finally check the dataset columns and rows of the modified data frame:
data.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 422281 entries, 27032 to 343939
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 category 422281 non-null category
1 text 422281 non-null object
2 words 422281 non-null int64
3 category_id 422281 non-null int8
dtypes: category(1), int64(1), int8(1), object(1)
memory usage: 10.5+ MB
time: 104 ms (started: 2022-03-01 12:16:14 +00:00)
Reduce the Size of the Total Dataset
Since using a large dataset for testing your pipeline would take more time, you would prefer to take a portion of the raw dataset as below:
#limit the number of samples to be used in code runs
#Total Number of Reviews is 427230
data_size= 427230
data= data[:data_size]
data.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 422281 entries, 27032 to 343939
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 category 422281 non-null category
1 text 422281 non-null object
2 words 422281 non-null int64
3 category_id 422281 non-null int8
dtypes: category(1), int64(1), int8(1), object(1)
memory usage: 10.5+ MB
time: 96.5 ms (started: 2022-03-01 12:16:14 +00:00)data.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 422281 entries, 27032 to 343939
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 category 422281 non-null category
1 text 422281 non-null object
2 words 422281 non-null int64
3 category_id 422281 non-null int8
dtypes: category(1), int64(1), int8(1), object(1)
memory usage: 10.5+ MB
time: 88.2 ms (started: 2022-03-01 12:16:14 +00:00)
Split the Raw Dataset into Train, Validation, and Test Datasets
To prevent data leakage during preprocessing the text data, we need to split the text into Train, Validation, and Test datasets.
Data leakage refers to a common mistake that we can make by accidentally sharing some information between the test and training datasets. Typically, when splitting a dataset into testing and training sets, the goal is to ensure that no data is shared between these two sets. This is because the test set’s purpose is to simulate real-world, unseen data. However, when evaluating a model, we do have full access to both our train and test sets, so it is up to us to ensure that no data in the training set is present in the test set.
In our case, since we want to classify reviews, we have to not use test reviews in preprocessing the text, especially during text vectorization and dictionary (vocabulary) generation.
Thus, before beginning the text preprocessing we will split the datasets as train, validation, and test.
NOTE: Even though in the fit() method, we have an argument validation_split for generating a holdout (validation) set from the training data, we can not use this parameter since we will use the tf.data.Dataset API to create the data pipeline. Because the argument validation_split is not supported when training from Dataset objects. Specifically, this feature (validation_split) requires the ability to index the samples of the datasets, which is not possible in general with the Dataset API.
Split Train & Test Datasets
# save features and targets from the 'data'
features, targets = data['text'], data['category_id']
all_train_features, test_features, all_train_targets, test_targets = train_test_split(
features, targets,
train_size=0.8,
test_size=0.2,
random_state=42,
shuffle = True,
stratify=targets
)time: 228 ms (started: 2022-03-01 12:16:14 +00:00)
Reduce the size of the Train Dataset
You might want to decrease the train dataset size to observe its impact on a Deep Learning model. Notice that I still keep the test data size fixed.
print("All Train Data Set size: ",len(all_train_features))
print("Test Data Set size: ",len(test_features))All Train Data Set size: 337824
Test Data Set size: 84457
time: 3.08 ms (started: 2022-03-01 12:16:14 +00:00)reduce_ratio = 0.02
reduced_train_features, _, reduced_train_targets, _ = train_test_split(
all_train_features, all_train_targets,
train_size=reduce_ratio,
random_state=42,
shuffle = True,
stratify=all_train_targets
)time: 189 ms (started: 2022-03-01 12:16:14 +00:00)print("Reduced Train Data Set size: ",len(reduced_train_features))
print("Test Data Set size: ",len(test_features))Reduced Train Data Set size: 6756
Test Data Set size: 84457
time: 2.8 ms (started: 2022-03-01 12:16:14 +00:00)
Split Train & Validation Datasets
train_features, val_features, train_targets, val_targets = train_test_split(
reduced_train_features, reduced_train_targets,
train_size=0.9,
random_state=42,
shuffle = True,
stratify=reduced_train_targets
)time: 16.6 ms (started: 2022-03-01 12:16:14 +00:00)print("Train Data Set size: ",len(train_features))
print("Validation Data Set size: ",len(val_features))
print("Test Data Set size: ",len(test_features))Train Data Set size: 6080
Validation Data Set size: 676
Test Data Set size: 84457
time: 7.57 ms (started: 2022-03-01 12:16:15 +00:00)
Summary
In this part, we prepared the datasets and took several actions and decisions:
- we converted categories from strings to integer ids
- we built look-up dictionaries for id to text and text to id conversion
- we split the dataset into Train, Validation, and Test sets.
In the next part, we will apply the text preprocessing by using the TF Data Pipeline and the Keras TextVectorization layer.
Do you have any questions or comments? Please share them in the comment section.
Thank you for your attention!